Swwiki
Introduction
Swwiki is a 2.8m-word corpus drawn from the Swahili Wikipedia as it was on 26 December 2015. When you enter a word in the search box above, up to 20 sentences in the corpus containing that word will be shown.
Creation
The pages and articles dump for 26/12/2015 was downloaded from the Wikimedia dump page. Giuseppe Attardi and Antonio Fuschetto's WikiExtractor tool was then used to extract plain text (discarding most markup etc) from the 165Mb dump, resulting in a 25Mb output file. This was tidied by removing remaining XML, blank lines, and blocks of English text.
The text was then split using the NLTK tokenize package, and these were imported into a PostgreSQL database table. The sentences were then pruned by removing all items less than 50 characters long, all duplicates, and all variant items (e.g. sentences giving the population of a specific place).
Key statistics
The final corpus contains total of 151,753 sentences containing 2,821,431 words. There are 172,998 tokens and 5,409 types (TTR 32), but a small percentage will be garbage (typos, errant brackets, etc).
The distribution of sentences by their wordcount is shown below:
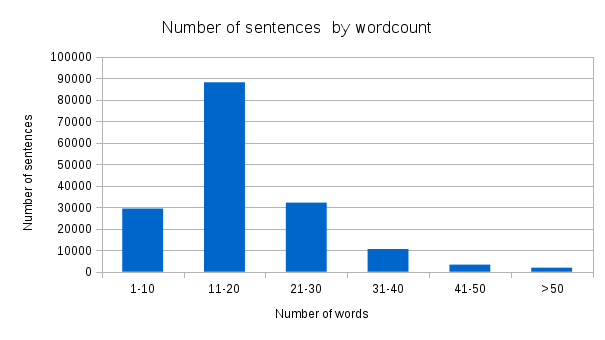
The commonest words (> 5,000 instances) are as follows:
| 183276 | ya | 13186 | mwaka | 7484 | watu | 6155 | wakati |
| 142598 | na | 12202 | nchini | 7202 | mji | 5765 | hii |
| 108506 | wa | 12085 | au | 7007 | kati | 5624 | moja |
| 54051 | kwa | 11266 | yake | 6825 | pamoja | 5539 | Tanzania |
| 49673 | katika | 9537 | kutoka | 6796 | lakini | 5464 | mara |
| 46691 | ni | 9296 | pia | 6766 | jina | 5411 | miaka |
| 33648 | la | 8737 | kwenye | 6593 | wake | 5147 | ambayo |
| 30420 | za | 8563 | vya | 6510 | kwanza | 5105 | juu |
| 19654 | kama | 8271 | lugha | 6382 | hadi | 5071 | sehemu |
| 18113 | cha | 7803 | zaidi | 6164 | alikuwa | 5015 | Katika |
| 13800 | kuwa | 7769 | nchi |
Downloads
The Swwiki corpus, which is licensed under the CC-BY-SA, can be downloaded below in csv format.
A frequency list of the words in the Swwiki corpus can be downloaded here in odf format.